
Статус:
Offline
Реєстрація: 11.03.2009
Повідом.: 656
Реєстрація: 11.03.2009
Повідом.: 656
PHP\MySQL: сложный постраничный вывод. Нужен help
Привет! Скажу сразу - я не программист, в жизни занимаюсь другими вещами. Но для "качания" мозга, изучаю РНР.
Сделать простой постраничный вывод я могу из базы данных простым LIMIT X, 10 к примеру.
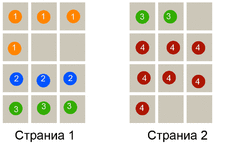
А вот как сделать такой сложный вывод? На приложеном файле сгенерированные 2 страница. Вернее как должны генерироваться.
Разные цвета - это разные категории. Номер категории на шарике. Шарик это разные элементы из категории. Количество категорий, элементов в категории - динамическое, т.е. можно менять.
Вопрос вот в чем. Как сделать так, чтоб информация сортировалась на листе с учетом того, что максимальное количество ячеек на 1 страницу - 12 штук.
Если категория занимает все 12 ячеек - оно идет сплошняком. Если категории занимают до 3х (включительно) клеточек, то следующая категория начинается со следующей строки.
Иными словами - каждая новая категория должна начинатся со следующего поля. Все последующие результаты должны смещаться вниз (вправо, как удобнее). На странице 2 видно продолжение.
Вывод страниц идет с параметром. Т.е. мне не надо сразу все листы выдать, а делать выборку. к примеру хочу отобразить только лист 2 и соотв. надо учесть, что первый элемент на листе 2 это продолжение категории ...
Не сильно запутанно? Мне нужна помощь - как бы это реализовать.
Исходные данные - база данных или один сплошной массив.
Привет! Скажу сразу - я не программист, в жизни занимаюсь другими вещами. Но для "качания" мозга, изучаю РНР.
Сделать простой постраничный вывод я могу из базы данных простым LIMIT X, 10 к примеру.
А вот как сделать такой сложный вывод? На приложеном файле сгенерированные 2 страница. Вернее как должны генерироваться.
Разные цвета - это разные категории. Номер категории на шарике. Шарик это разные элементы из категории. Количество категорий, элементов в категории - динамическое, т.е. можно менять.
Вопрос вот в чем. Как сделать так, чтоб информация сортировалась на листе с учетом того, что максимальное количество ячеек на 1 страницу - 12 штук.
Если категория занимает все 12 ячеек - оно идет сплошняком. Если категории занимают до 3х (включительно) клеточек, то следующая категория начинается со следующей строки.
Иными словами - каждая новая категория должна начинатся со следующего поля. Все последующие результаты должны смещаться вниз (вправо, как удобнее). На странице 2 видно продолжение.
Вывод страниц идет с параметром. Т.е. мне не надо сразу все листы выдать, а делать выборку. к примеру хочу отобразить только лист 2 и соотв. надо учесть, что первый элемент на листе 2 это продолжение категории ...
Не сильно запутанно? Мне нужна помощь - как бы это реализовать.
Исходные данные - база данных или один сплошной массив.
 :)")
 ;)")
 .
.